Eine Partialkorrelation mit R rechnen
Wie berechnet man eine Partialkorrelation?
|
Eine Partialkorrelation klärt die Frage, ob zwei Variablen immer noch korrelieren, wenn man eine dritte Variable "abzieht" (herauspartialisiert).
Beispiel: An den Daten eines Sommers ergibt sich eine Korrelation zwischen der Menge an verkaufter Eiskreme und der Häufigkeit von
Sonnenbränden. Verursacht Eiskreme, dann einen Sonnenbrand? Natürlich nicht, der dritte Faktor ist die Anzahl an täglichen Sonnenstunden,
diese ist höher, wenn auch viel Eiskreme verkauft wird und mit jeder weiteren Sonnenstunden steigt die Anzahl an Sonnenbränden.
Ich würde empfehlen, die Rangvarianzanalyse mit dem R zu rechnen. Kopieren Sie die nachfolgenden 3 Zeilen in Ihr R-Studio. Wir erstellen zuerst Zufallsdaten (x, y, z, wobei x = Eiskrememenge, y = Sonnenbrände, z = Drittvariable Sonnenstunden), dann rechnen wir den Einfluß von z (Sonnenstunden) weg.
set.seed(123)
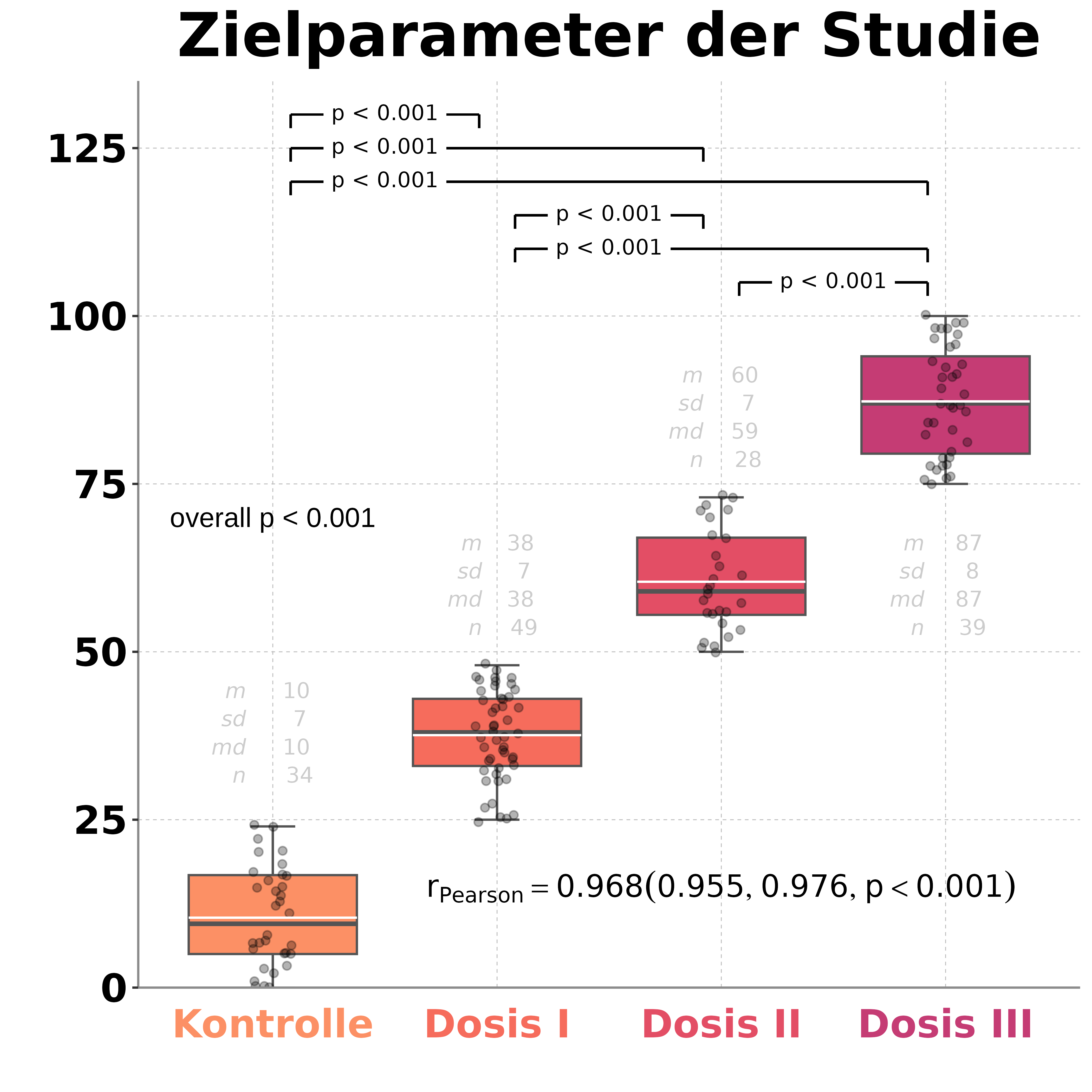
z <- 0.5 * x + 2 * y + rnorm(50) Baut man das ganze nun in einen data.frame, partialisiert die Werte heraus, d.h. man verwendet ab jetzt die z-freien Werte von x und z-freien Werte von y (die jeweils vorhergesagten Residuen werden abgezogen), dann erhält man eine wesentlich geringere und deutlich näher bei Null liegende Korrelation von r = 0.132.
FazitEine Scheinkorrelation kann mit Hilfe einer Drittvariablen bereinigt werden, der r-Wert bewegt sich dann in die Nähe einer Nullkorrelation. Der Verbrauch von Eiskreme, dessen Höhe erst mit der Anzahl an Sonnenbränden scheinbar korrelierte (r = 0.895), fällt in sich zusammen (r = 0.132), wenn man die Anzahl der Sonnenstunden berücksichtigt. Diese bestimmte sowohl den Eiskremeverkauf, als auch das Auftreten von Sonnenbränden. Zieht man den Einfluß von letzterem ab, fällt die Schein-Korrelation wie ein Kartenhaus in sich zusammen. |