Einen t-Test rechnen
Einen t-Test rechnen
|
Ein T-Test klärt die Frage "Unterscheiden sich meine zwei Gruppen nun, oder nicht?"
Die Nullhypothese lautet auf keine Unterschiede, die Alternativhypothese, dass zwischen den Gruppen Unterschiede existieren.
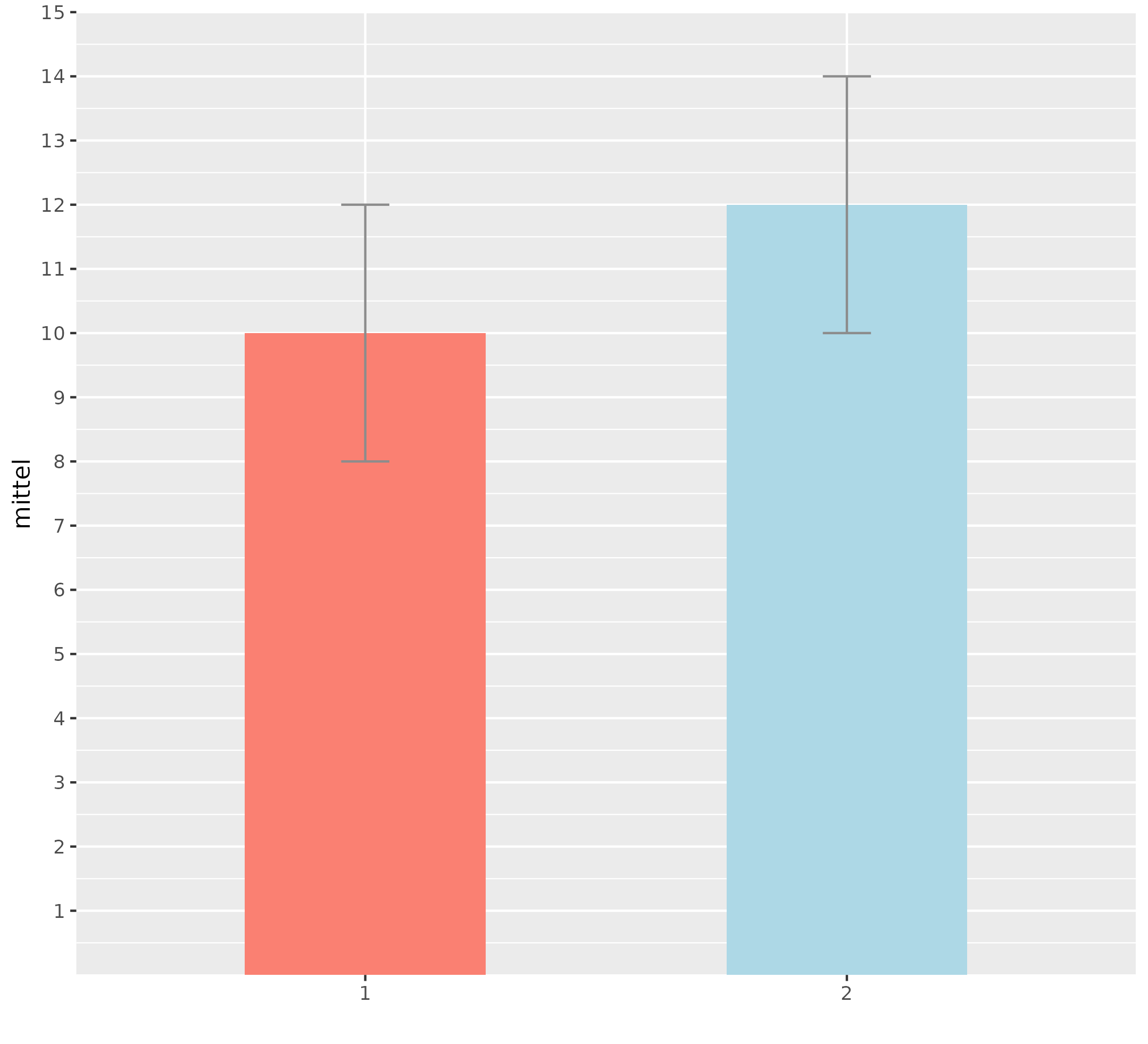
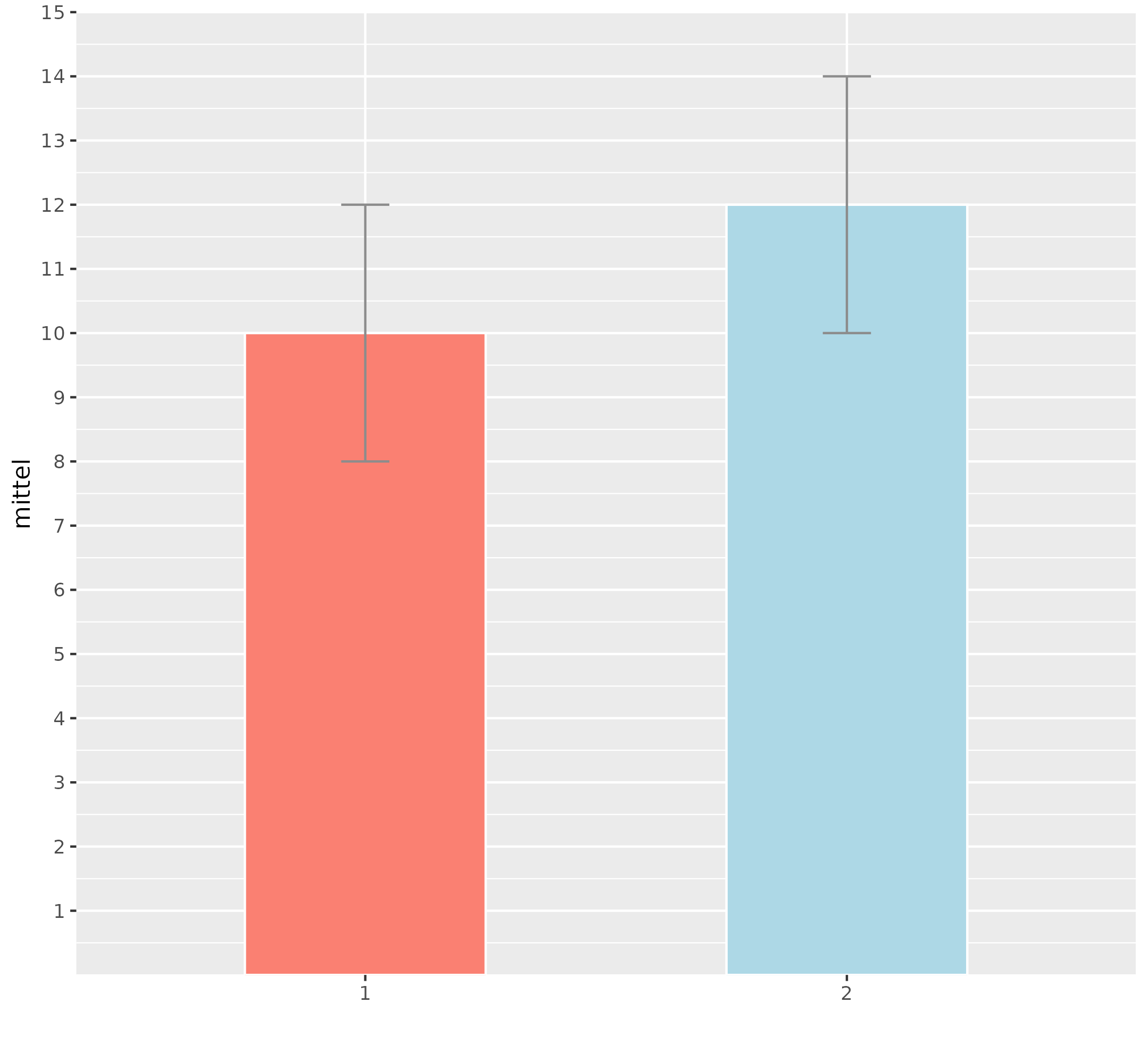
Man möchte, die Nullhypothese verwerfen und die Alternativhypothese annehmen.Man braucht eine Zielvariable ("worin sollen sich meine Gruppen unterscheiden?") und eine Gruppeneinteilung mit genau 2 Stufen. Ein Beispiel: 2 Altersgruppen (≤> 65 Jahre) und Rückenschmerz als Score auf einer Skala von 0 (kein) - 10 (unerträglich). Hier würde ein t-Test prüfen, ob es einen Zusammenhang zwischen Alter und Schmerz gibt, speziell, ob sich die Altersgruppen unterscheiden. Interpretativ könnte man das am Ende so sagen (wenn p ≤ 0.05): "je älter desto Rücken". Tipp: Ersetzen Sie die zwei Merkmale aus dem obigen Beispiel einfach mit zwei Merkmalen aus Ihren eigenen Daten, z.B. Gruppe (A/B) versus ein eigenes kontinuierliches Merkmal. | ||||||||||||||||||
Sie müssen schnell einen t-Test rechnen, einen t-Test mit Excel rechnen
Wenn es schnell gehen muss, nehmen Sie Excel, hier ist der t-Test eingebaut (Funktion "TTEST").
Da dieser p-Wert p ≤ 0.05, können Sie die Nullhypothese ("kein Unterschied") ablehnen, was plausibel macht, dass sich die Gruppen unterscheiden. Aber Vorsicht, nicht immer stimmen die voraussetzungen dieses Tests (z.B. Normalverteilung, das sollte abgeklärt werden). Einen t-Test mit R rechnen
Mit R oder RStudio geht es so (Ziffern der obigen Tabelle werden erst eingegeben):
data = data.frame(group = c(1,1,1,1,0,0,0,0), score = c(5, 10, 8, 7, 2, 3, 2, 4))
Die Tilde, d.h. das Zeichen ~ zeigt an, was vorhergesagt werden soll. Hier liest man von rechts
nach links, d.h. aus der Gruppenzugehörigkeit soll der Schmerz-Score vorhergesagt werden.summary(t.test(score ~ group, data = data)) Einen t-Test mit SPSS rechnen
Machen Sie im SPSS ein Syntax-Fenster auf (Datei | Neu | Syntax) und kopieren Sie diese Zeilen hinein.
data list list /group (f8) score (f8).
Alles markieren (oder Strg + a), dann die Run-Taste (grünes Dreieck) oder Strg + r.begin data 1 5 1 10 1 8 1 7 0 2 0 3 0 2 0 4 end data. t-test groups = group(0,1) /variables score. Vorteile und Nachteile, eine kurze Abwägung
Ein t-Test hat Nachteile. Es sind die recht vielen Annahmen.Er basiert im Prinzip auf dem allgemeinen linearen Modell, d.h. bei jedem Testlauf läuft im Hintergrund eine Regression. Die Idee ist, dass die Gruppenzugehörigkeit (z.B. Diagnose A vs. B) einen Wertebereich vorhersagt (Besserungs-Scores), für die der Mittelwert auch der beste Schätzer ist. Dementsprechend braucht man (strengnommen) alle Voraussetzung einer linearer Regression, darunter eine Normalverteilung der Fehler (genauer Fehlvorhersagen aus der Gruppenzugehörigkeit, man nennt diese Fehler "Residuen"), eine homogene Varianzen der Residuen, eine lineare Beziehung zwischen den Prädiktor und Zielvariable Unabhängikeit der Residuen Diese vielen Annahmen können natürlich gestestet werden und sind leider entsprechend schnell verletzt, so dass man sich eigentlich von vorneherein auf den U-Test einschießen sollte. Dieser Test ist nahezu frei von solchen Annahmen und kann fast immer bedenkenlos verwendet werden. SPSS, R, und andere Apps für die Statistik
SPSS Weitere Links
SPSS, das Allround-Knife SPSS, R anderes Rechengerät
SPSSPSPP als freie Alternative R als Alternative |