Eine einfache Korrelation mit R rechnen
Wie berechnet man einen Korrelationskoeffizienten?
Die Korrelation nach Pearson (größer-größer oder größer-kleiner Zusammenhang)Voraussetzung für eine einfache Korrelation sind zwei Datenspalten
Ich würde empfehlen, den Korrelations-Koeffizienten mit dem R zu rechnen. Kopieren Sie diese Zeilen in Ihr R-Studio.
data = data.frame(dosis = c(10,8,9,5,4,1,2,1), besserung = c(5,3,5,4,2,0,0,0))
t = 6.2714, df = 6, p-value = 0.0007638 Die Rangkorrelation nach SpearmanEs gibt auch eine sogenannte Rangkorrelation (nach Spearman). Hier werden die Rohwerte in der obigen Tabelle vorher in Ränge umgewandelt. Geben Sie als "method" dann "spearman" an und die Berechnungsmethode ist die gleiche wie im vorherigen Beispiel. Die Rangumwandlung hat den Vorteil, dass Ausreißerwerte nicht mehr ein so großes Gewicht haben. Sie bekommen einfach den höchsten Rang. Einfach in der obigen Zeile das "pearson" durch ein "spearman" ersetzen, die Ausgabe ist genau wie oben zu interpretieren.
cor.test(data$dosis, data$besserung, method = "spearman") Die punktbiseriale KorrelationPunkt-biserial meint, dass in einer Spalte die Werte nur aus 0 oder 1 bestehen, z.B. Dosis 0 vs. Dosis 1 oder Gruppe A vs. nicht A. An den Berechnungen ändert sich hier nichts, gleiches Vorgehen wie oben. Es reicht, wenn der cor-Wert und der p-Wert interpretiert werden.
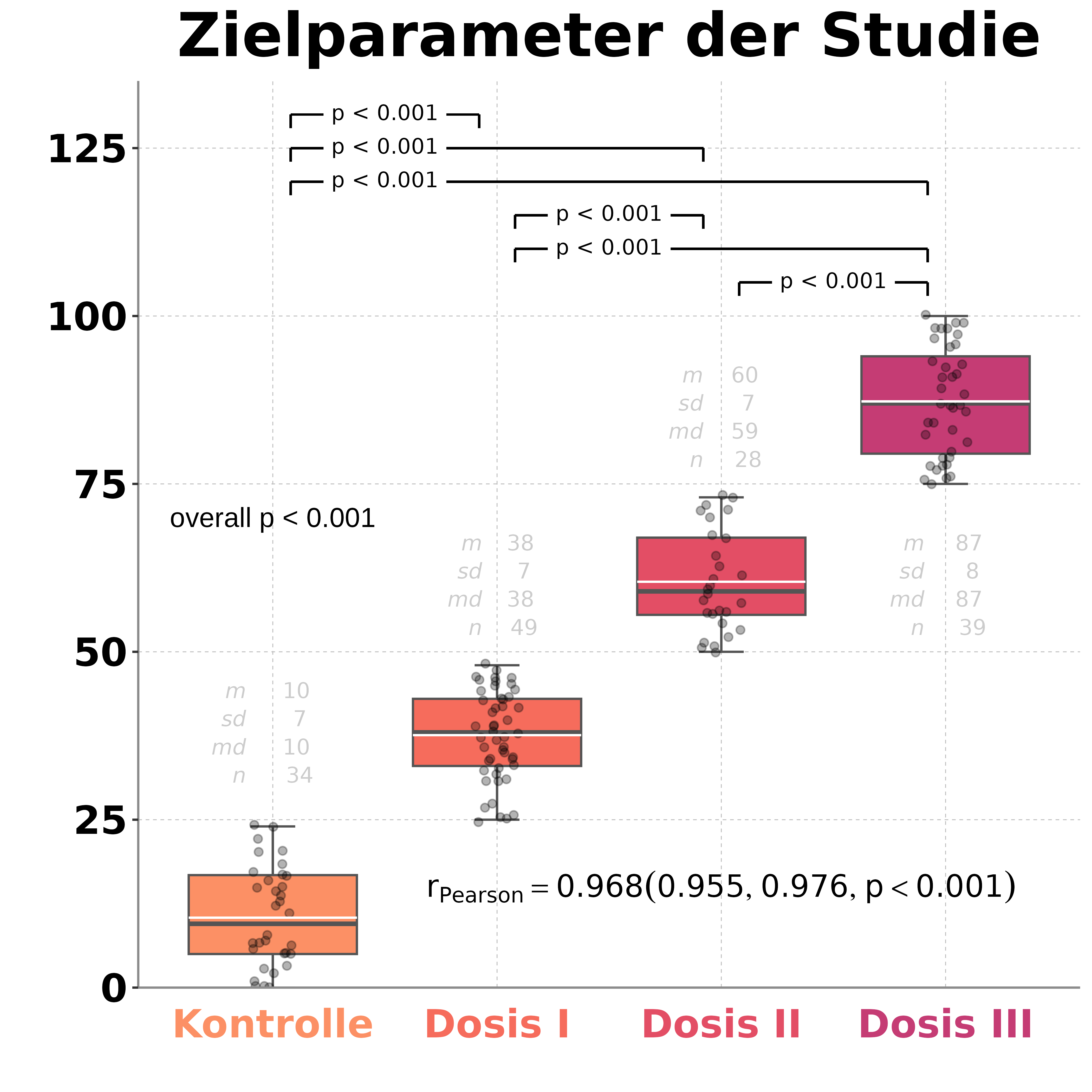
cor.test(data$dosis, data$besserung, method = "pearson") Bewertung der KorrelationDie Höhe der Korrelationkann nach Schwellen bewertet werden (siehe z.B. Cohen: Statistical Power Analysis for the Behavioral Sciences, 1988). Er setzt folgende Grenzen für einen Korrelationskoeffizienteneine signifikante Korrelation ab 0,1 kann als "schwacher Zusammenhang" bewertet werden. eine signifikante Korrelation ab 0,3 kann als "mittelstarker Zusammenhang" bewertet werden. eine signifikante Korrelation ab 0,5 kann als "starker Zusammenhang" bewertet werden. Eine Korrelation von r = 0.7 kann man somit als einen starken positiven (d.h. gleich-gerichteten) Größer-Größer-Zusammenhang interpretieren. |